rpa_browser_getElementHtml
获取网页元素的Html代码,网页元素需要提前使用“捕获网页元素”功能捕获,并保存
1. 函数
rpa_browser_getElementHtml(tabId, elementId, index=0, waitElement=True, parentElement="")
- tabId: 字符串类型,网页标识;
- elementId:字符串类型,网页元素标识;
- index: 整型,若匹配到多个元素,操作的元素序号,索引从0开始;
- waitElement: 布尔型,是否等待元素出现;
- parentElement: 父元素描述字符串,通过rpa_browser_getElement接口返回,表示元素的查找范围,传空字符串表示从根目录开始查找元素。
2. 返回值
返回指定网页元素的Html代码,字符串类型。
若返回的字符串不为空,表示获取成功;若返回的字符串为空,表示获取失败,通过rpa_getLastErrorCode()获取错误码,rpa_getLastErrorMsg()获取错误信息。
3. 示例
# 打开百度
tabId = rpa_browser_openUrl('www.baidu.com')
# 获取元素个数
totalCount = rpa_browser_getElementCount(tabId, "a标签", waitElement=True)
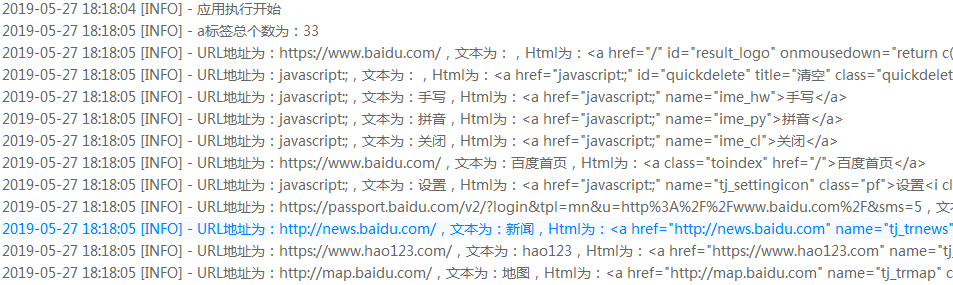
print('a标签总个数为:%d'%(totalCount))
# 获取所有a标签的数据
for index in range(totalCount):
url = rpa_browser_getElementUrl(tabId, "a标签", index, False)
text = rpa_browser_getElementText(tabId, "a标签", index, False)
html = rpa_browser_getElementHtml(tabId, "a标签", index, False)
# # 忽略部分
# if url == 'javascript:;':
# continue
print('URL地址为:%s,文本为:%s,Html为:%s'%(url, text, html))
其中,网页元素“a标签”的属性为:
- @selector【等于】a
输出内容的部分截图: