浏览器表格数据抓取
1. 什么是表格元素
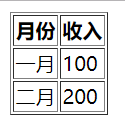
表格是html中标签为table的元素,比如下面的table就是一个表格(本文后面的代码都以此表格为例):
<table border="1">
<tr>
<th>月份</th>
<th>收入</th>
</tr>
<tr>
<td>一月</td>
<td>100</td>
</tr>
<tr>
<td>二月</td>
<td>200</td>
</tr>
</table>
2. 获取表格对象的两种方法
使用rpa_browser_getTableTextByText函数通过表格中出现的文本片段获取表格对象:
tableInfo = rpa_browser_getTableTextByText(tabId, "月份")第一个参数是页签id,第二个参数是表格中出现的文本,返回表格对象
使用rpa_browser_getTableTextByHtml函数通过表格的html源代码片段获取表格对象:
tableInfo = rpa_browser_getTableTextByHtml(tabId, '<table border="1">')第一个参数是页签id,第二个参数是表格中出现的html源码,返回表格对象
3. 获取表格行列数
函数rpa_browser_getTableRowCount可以获取表格行数:
rowCount = rpa_browser_getTableRowCount(tableInfo)参数为表格对象,返回行数,在这个例子中为3。
函数rpa_browser_getTableColCount可以获取表格列数:
columnCount = rpa_browser_getTableColCount(tableInfo)参数为表格对象,返回列数,在这个例子中为2。
4. 获取单元格内容
函数rpa_browser_readTableInfo可以获取表格的单元格内容:
info = rpa_browser_readTableInfo(tableInfo, 1, 0)
第一个参数是表格对象,第二个参数是行号(从0开始),第三个参数是列号(从0开始)。
上面的代码获取表格第二行第一列的内容,返回“一月”。
5. 获取表格html源码对象的两种方法
如果要获取包含html源码的表格对象,需要使用下面的函数。
使用rpa_browser_getTableHtmlByText函数通过表格中出现的文本片段获取表格对象:
tableInfo = rpa_browser_getTableHtmlByText(tabId, "月份")第一个参数是页签id,第二个参数是表格中出现的文本,返回表格对象
或者使用rpa_browser_getTableHtmlByHtml函数通过表格的html源代码片段获取表格对象:
tableInfo = rpa_browser_getTableHtmlByHtml(tabId1, '<table border="1">')第一个参数是页签id,第二个参数是表格中出现的html源码,返回表格对象
此时通过rpa_browser_readTableInfo函数获得的单元格内容是源码内容,例如:
info = rpa_browser_readTableInfo(tableInfo, 1, 0)
上面的代码获取表格第二行第一列(行列号都从0开始)的内容,返回“